데이터 모델링의 문제
- 데이터 모델링이 제기하는 문제는 물리적인 실체를 묘사하는 논리적 데이터를 어디에(어떤 테이블/스키마에) 둘 것인가?"라는 논리적인 결정
- 더 구체적으로 말하면 데이터를 기존의 테이블 내에서 다른 데이터들과 한 곳에 둘지(통합), 나눌지(분리) 결정이 필요함
- 정규화의 문제 (Normalization): 데이터 구조 중심
- 목표: 데이터의 중복 제거와 결함(Anomaly) 방지.
- 기준: 수학적/논리적 무결성. (예: "학번이 결정되면 이름이 결정되니 분리하자.")
- 결과: 실체가 무엇이든 상관없이, 데이터 간의 종속 관계에 따라 기계적으로 테이블을 쪼갭니다.
- DDD의 문제 (도메인 주도 설계): 비즈니스 행위 중심
- 목표: 변경의 전파 차단과 비즈니스 복잡도 해결.
- 기준: 비즈니스 맥락(Context)과 트랜잭션의 범위(Aggregate).
- 결과: 하나의 물리적 실체라도 "이 기능과 저 기능은 남남이야"라고 판단되면 테이블을 찢어버립니다. (불일치의 허용)
도메인 설계(Domain Design)란 무엇인가?
쉽게 말해 "현실 세계의 복잡한 비즈니스 규칙을 소프트웨어 코드로 옮기는 설계 과정*입니다.
- 도메인(Domain): 소프트웨어가 해결하고자 하는 "업무 영역(Business World)" 그 자체입니다. (예: 쇼핑몰의 결제, 배송, 재고 관리 등)
- 설계(Design): 그 영역에서 일어나는 일들을 어떻게 구조화하고 코드/모델로 구현할지 결정하는 것
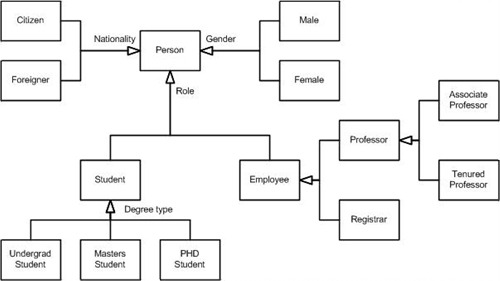
DDD가 관심있는 문제
문제 정의: "실체(Entity)와 모델(Model)의 불일치를 언제 어떻게 허용할 것이냐"
- 현실의 실체 (Physical Entity): 세상에 딱 하나 존재하는 물리적 객체죠. 예를 들면 현실에서의 '종이컵' 그 자체.
- 소프트웨어의 모델 (Logical Model): 물리적 객체를(그 종이컵)을 '어떤 목적'으로 바라보느냐에 따라 추출된 데이터의 집합입니다.
즉, DDD 설계방식이란 "물리적인 종이컵이 하나라고 해서, DB 테이블(모델)도 하나여야 하는가?"에 대해 "아니오, 목적에 따라 여러 개로 찢어야 합니다"라고 답하는 설계방식.
DDD가 제기하는 문제 : 과도한 데이터 통합의 문제점
단순히 하나의 테이블에 칼럼을 계속 추가하면서 유지보수하면 되지않나?
1. 기술적 측면: 자원 경합과 성능 (Resource Contention)
하나의 거대 테이블(God Table)에 모든 데이터가 모이면 생기는 물리적 병목입니다.
- 잠금 경합(Lock Contention): 배송팀이 배송지 정보를 수정할 때, 상품팀의 상품명 수정이 대기해야 할 수도 있습니다. 테이블 수준의 락이 걸리면 시스템 전체가 느려집니다.
- 인덱스 비대화: 수백 개의 컬럼 중 조회 조건이 다양하니 인덱스도 수십 개가 붙습니다. 그러면 데이터를 하나 넣을 때마다 인덱스 수십 개를 업데이트해야 해서 저장(Insert/Update) 성능이 처참해집니다.
- I/O 낭비: 특정 상품의 가격만 조회하고 싶은데, DB는 수백 개의 컬럼이 포함된 한 줄(Row) 전체를 메모리로 읽어와야 합니다.
2. 유지보수 측면: 인지 부하와 분기 지옥 (Cognitive Load)
개발자가 코드를 읽고 수정할 때 겪는 뇌의 과부하 문제입니다.
- 필드 이해의 늪: Product 클래스에 필드가 200개라면, "이 필드는 누가 쓰지? 내가 고쳐도 되나?"를 판단하는 데만 하루가 다릅니다.
- 분기 처리(If-Else)의 파편화: 서비스 곳곳에 if (type == 'A') ... else if (type == 'B')가 흩어져 있습니다. 나중에 type 'C'가 추가되면 수만 줄의 코드에서 이 if문들을 찾아다니며 수정해야 합니다. 하나라도 놓치면 버그가 되죠
핵심 아이디어: 바운디드 컨텍스트 (Bounded Context)와 애그리게이트(Aggregate)
거시적 분리 기준: 바운디드 컨텍스트 (Bounded Context)
그렇다면, 하나의 물리적 실체에 대한 데이터를 언제 여러개의 DB 테이블(모델)로 찢어야하는가? A : 바운디드 컨텍스트가 다를때.
바인디드 컨텍스트는 학술적 정의로 "특정 모델이 정의되고 적용되는 논리적인 경계(Boundary)" 이며 이 경계 안에서는 어떤 단어가 오직 하나의 의미로만 해석되어야함.
- 바운디드 컨텍스트 A (판매): 종이컵을 '상품(Product)' 으로 정의. (관련데이터: 가격, 할인율, 상품이미지)
- 바운디드 컨텍스트 B (재고): 종이컵을 '재고 항목(Inventory Item)'으로 정의. (관련 데이터 : 바코드, 창고위치, 무게)
의미가 다르다 = 관심사(관점)가 다르다, 로직(규칙)이 다르다. 똑같은 물리적 객체를 보더라도, 각 로직이 관심을 갖는 데이터(필드) 자체가 다릅니다. 데이터가 다르며 그 데이터를 다루는 비즈니스 로직(상태 변화의 규칙)과 목적이 다르다.
- 주문 로직: "누가 언제 샀는가?"가 핵심. (결제 시점 중요),
- 재고 로직: "지금 창고에 몇 개 남았는가?"가 핵심. (입출고 시점 중요)
미시적 분리 기준: 애그리거트 (Aggregate)
애그리거트는 수정 시 '항상 함께 움직여야 하는 최소 단위'를 의미합니다.
- 데이터의 원자적 변경 (Transactional Consistency) "A를 바꿀 때 B를 동시에 바꾸지 않으면 시스템에 '에러'나 '산술적 오류'가 발생하는가?"
- 비즈니스 불변식의 강제 (Invariants) :"객체의 상태가 변할 때 반드시 지켜져야 하는 '절대 규칙'이 있는가?"
같은 컨텍스트 안에서도 "데이터가 변경되는 생명주기(Lifecycle)가 다르면" 테이블을 찢어야 합니다.
- 함께 움직이는 경우 (통합): '주문'이 생성될 때 '주문 상세 항목'들은 무조건 같이 생성되어야 합니다. 이들은 하나의 애그리거트로서 보통 같은 DB 트랜잭션으로 처리됩니다.
- 따로 움직이는 경우 (분리):
- 상황:주문이 생성된 후, 고객이 취소를 요청하면 취소 사유와 취소 일시 등을 기록해야 합니다.
- 왜 찢나? (Aggregate 분리 기준):
- 생성 시점: 주문은 '구매' 시점에 생기지만, 취소 이력은 '취소' 사건이 터져야 생깁니다.
- 데이터의 성격: 주문은 현재의 **'상태'**가 중요하지만, 취소 이력은 일종의 **'로그(Log)'**입니다.
- 성능: 주문 상세 정보를 조회할 때마다 굳이 (대부분 존재하지도 않는) 취소 이력 테이블까지 조인해서 가져올 필요가 없습니다.
- 결론: 같은 주문 팀이 관리하지만, Order와 OrderCancellation은 별도의 애그리거트로 분리합니다.
- 상황: 주문 시 쿠폰 할인, 포인트 할인, 이벤트 할인 등 여러 혜택이 적용됩니다.
- 왜 찢나? (Aggregate 분리 기준):
- 불변성: 주문의 상태(배송중, 완료)는 계속 변하지만, '어떤 할인을 받았는가'에 대한 기록은 결제 시점에 확정되면 절대 변하지 않습니다.
- 복잡도 격리: 할인 혜택의 종류가 수십 가지로 늘어나도, 핵심 주문 로직(배송지 변경, 상태 변경 등)은 영향을 받지 않아야 합니다.
- 결론: 핵심 주문 정보(Order)와 할인 적용 내역(DiscountUsage)을 분리하여, 주문 수정 시 할인 내역 테이블에 락(Lock)이 걸리는 것을 방지합니다.
DDD의 바운디드 컨텍스트 분리 적용
구조:
- USER (기본 키: user_id)
- USER_MARKETING ( user_id, 마케팅 동의 여부, 유효기간)
- USER_PRIVACY ( user_id, 실명, 주민번호, 법적 보관 기한)
테이블간 무결성 보장방식 : FK 대신 '식별자 공유(Shared Identity)'라는 개념을 씁니다.
- ID만 공유: user_id가 100번인 사용자가 있다면, 마케팅 DB에도 ID 100이 있고 법무 DB에도 ID 100이 있습니다.
- 연관 관계 끊기: 두 테이블 사이에 DB 수준의 FK 제약조건은 걸지 않습니다.
- 이벤트 기반 동기화(Saga Pattern): 만약 사용자가 "회원 탈퇴"를 하면, '사용자 탈퇴 이벤트'가 발생하고, 마케팅 시스템과 법무 시스템은 각자 자기 맥락에 맞는 로직(1년 뒤 삭제 vs 즉시 삭제)을 스스로 수행합니다.
FK를 안쓰는 이유
- 잠금 경합 (Lock Contention): 데이터베이스는 인덱스를 수정하거나 대량의 데이터를 업데이트할 때 테이블이나 페이지 단위로 락을 겁니다.
- 자식 테이블 CUD 시: 부모 행에 S-Lock을 겁니다. ( FK 참조 무결성을 확인하는 순간만큼은 부모 행에 S-Lock을 겁니다. 부모가 수정 중이면 자식은 대기해야 함)
- 부모 테이블 CUD 시: 부모 행에 X-Lock(배타적 잠금)을 겁니다. (이때 자식 테이블에 새 데이터를 넣으려는 시도들은 부모의 S-Lock 획득이 불가능해지므로 모두 대기 상태가 됨)
- 스키마 변경의 영향 : 부모 테이블 컬럼 타입을 바꿉니다. DDL 작업 시 테이블 전체에 **메타데이터 락(Metadata Lock)**을 겁니다. 이 순간부터는 자식 테이블의 INSERT를 위한 단순 부모 Read조차 막힙니다.
- 가용성 전파: UserTable이 있는 DB 서버 자체가 죽으면 마케팅이고 법무고 서비스 전체가 마비됩니다.
DDD의 Trade-off
이벤트 드리븐과 Saga가 "완전한 DDD"를 만들어주지만, 개발자에게는 다음과 같은 새로운 고통을 줍니다.
- 추적의 어려움: "분명 가입은 됐는데 왜 쿠폰은 안 들어왔지?"를 확인하려면 여러 서비스의 로그를 다 뒤져야 합니다. (Distributed Tracing의 필요성)
- 디버깅 지옥: 코드를 따라가다 보면 갑자기 이벤트 큐로 사라지니, 로직의 흐름을 한눈에 파악하기 어렵습니다.
- 인프라 복잡도: Kafka나 RabbitMQ 같은 메시지 브로커를 관리해야 하는 운영 부담이 생깁니다.
DDD 관점 설계의사결정 예시1 : 라벨 표시제어 및 통계제어 기능추가
1. 현황 및 신규 요구사항
- 기존 기능: 회사별 라벨 명칭 커스텀 관리
- 기존 테이블: company_config (라벨 설정 테이블)
- 기존 속성:
- label_name: 커스텀 된 라벨의 이름
- datastatus: 회사 삭제시 라벨 데이터의 생명주기 관리 (active, inactive, delete)
- 신규 요구사항:
- 특정 회사의 라벨을 화면에서 숨기는(Hidden) 기능 추가
- 라벨 숨김 시, 해당 라벨에 대한 데이터 배치 집계도 중단 (정책적 일치)
2. 설계 쟁점: 두 가지 관점의 대립
입장 1: 신규 테이블 생성으로(애그리거트) 분리가 필요함
[근거: DDD - Aggregate & Context]
- 책임의 분리: '라벨의 명칭(데이터 내용)'과 '라벨의 노출 여부(상태 제어)' 그리고 '배치집계'는 서로 다른 도메인 맥락(Context)을 가집니다. 이를 하나의 테이블에 두면 애그리거트가 비대해집니다.
- 확장성 가능성: 나중에 "명칭은 유지하되 UI에서만 숨기고, 배치는 계속 돌아야 한다"는 식으로 정책이 분리될 경우, 분리된 설계가 훨씬 유연하게 대응할 수 있습니다.
- 모델의 순수성: datastatus는 레코드의 물리적 생존을 담당해야 하며, 비즈니스 옵션을 여기에 끼워 넣는 것은 모델 오염입니다.
입장 2: 테이블의 확장(기존 필드 활용)이 필요함
[근거: YAGNI & Logic Hierarchy]
- "도메인 응집도 (Domain Cohesion): 라벨의 '명칭'은 라벨이 '활성 상태(Active)'일 때만 비즈니스적 의미를 가집니다. 이처럼 두 데이터는 비즈니스 활용 측면에서 상호 의존도가 매우 높으므로, 이를 별도 테이블로 분리하여 관리 포인트를 늘리기보다 하나의 테이블(company_config)에 통합하여 관리하는 것이 조회 편의성과 도메인 개념의 직관성을 높이는 길입니다.
- 실용주의(YAGNI): "숨김 = 배치 중단"이라는 정책이 확고하다면, 불필요하게 테이블을 찢는 것은 과잉 설계입니다. 현재 쓰지 않는 inactive 필드를 활용하는 것이 가장 빠르고 효율적인 해결책입니다.
- 상태의 포함 관계: delete(삭제)는 논리적으로 inactive(미사용)를 포함하는 상태입니다. 회사가 삭제되면 사용 여부를 따질 필요가 없으므로, 단일 필드에서 Active → Inactive → Delete로 이어지는 계층적 상태 관리가 더 직관적입니다.
3. 최종 결정: 입장 2(기존 필드 활용) 채택
[결론: 도메인 정책에 기반한 실용적 최적화]
- 정책적 정당성: "라벨 숨김은 곧 해당 기능의 중단(배치 중단)"이라는 도메인 정책이 확고하므로, 이를 별도 컬럼으로 나누기보다 datastatus = 'inactive'라는 명확한 상태값으로 표현하는 것이 도메인 모델에 더 가깝다고 판단함.
- 구조적 단순화: 새로운 테이블이나 컬럼을 추가하지 않고 기존의 유휴 속성을 활용함으로써, 시스템 복잡도를 낮추고 배치 쿼리의 조건절(WHERE status = 'active')을 그대로 유지할 수 있는 이점을 취함.
- 향후 과제: 코드 레벨에서 isLabelDisabled()와 같은 명시적인 도메인 메서드를 통해 inactive의 비즈니스 의미를 캡슐화하여, 추후 정책 분리 시 리팩토링 범위를 최소화함.
'개발기술 > RDB' 카테고리의 다른 글
| DB 데이터 탐색방식 (0) | 2026.01.13 |
|---|---|
| 데이터모델링 방법론 : 정규화 (0) | 2026.01.04 |
| DB 마이그레이션 (1) | 2025.11.15 |
| 데이터베이스 저장구조 (0) | 2025.08.18 |
| 데이터베이스 쿼리 동작분석 및 튜닝 (2) | 2025.07.14 |
