Persistence Framework
데이터영속성(Persistence)이란 프로그램이 꺼져도 데이터는 사라지지 않는 것, 즉, 영구저장 DB를 사용하는 데이터를 말함. DB를 다루기 위해 필요한 프레임워크를 Persistence Framework라고 한다.
Persistence Framework를 사용하면, DB관련되어 개발자가 공통적으로 작성하는 코드를 대신하여 동작시켜주어, 코드 재사용 및 유지보수에 용이하며 코드가 직관적이다.
1. DB연결 : MongoDB, Reddis, Mysql 등에 맞는 코드를 Framework가 대신 동작하여 DB에 종속적이지 않도록 해준다
2. DB와의 연결상태에 따른 코드를 Framework가 대신 동작하여 DB의 연결에 대한 관리를 대신해줌
- DB와 최초 연결시 DB연결 Fail Exception Handling
- Query 실행시 Query동작 Fail Exception Handling
- DB가 지속적으로 연결되어있는지 중간에 확인동작, DB연결이 끊겼을때 ExceptionHandling
- DB사용이 끝나면 연결끊는 동작
위의 경우를 모두 if/else 그리고 try/catch문으로 처리해주어야해서 어려움이 많음.
SQL mapper와 ORM
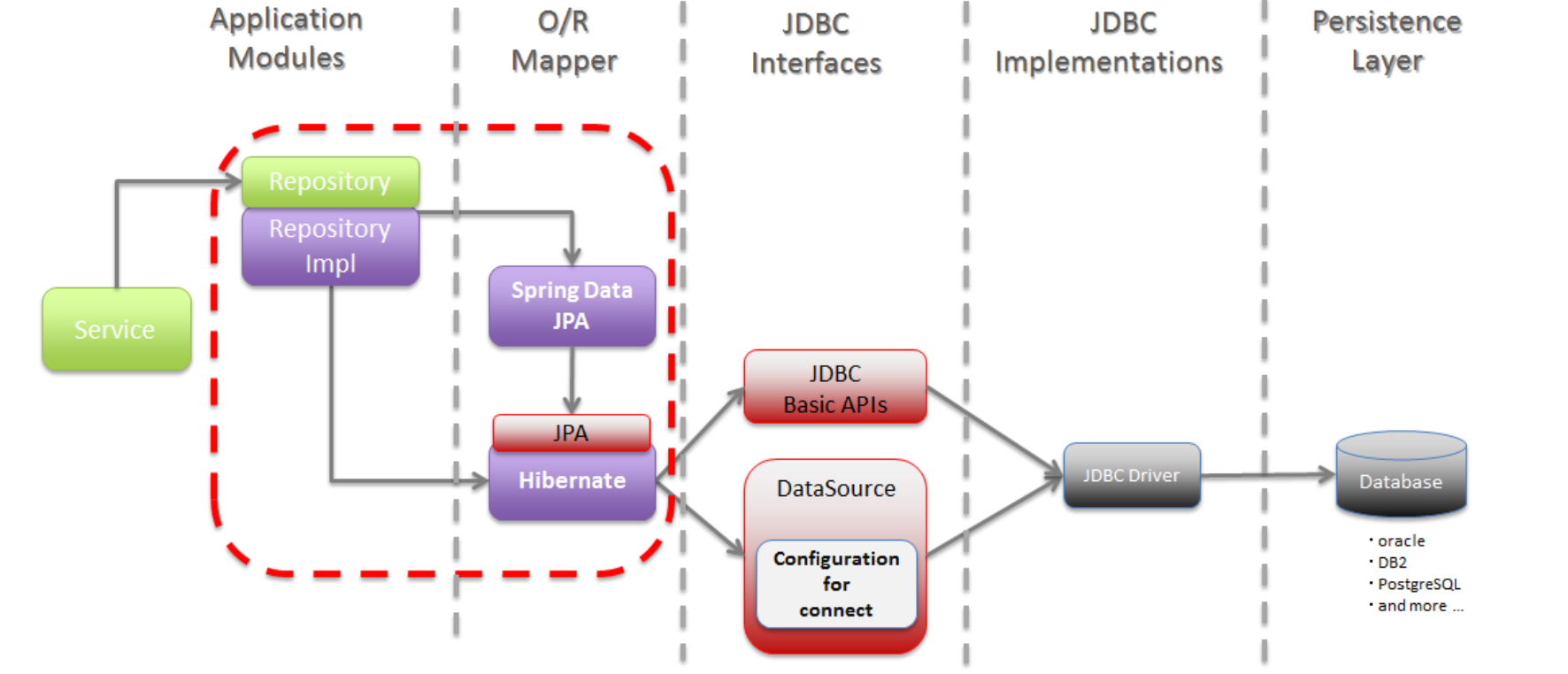
Persistence Framework는 SQL mapper와 ORM(Object Relation Mapping) 두종류가 있음. SQL mapper는 개발자가 직접 sql쿼리문을 작성하는 반면, ORM은 java의 Object를 db의 테이블과 직접 관계를 맺도록하여 sql문을 사용할 필요 없도록 함. 단, 복잡한 쿼리가 필요한 작업은 SQL작성이 필요할때가 있음. SQL mapper는 DB에 따라서 SQL문을 수정해주어야해서 DB종속적인 반면 ORM은 프레임워크 자체적으로 sql문을 작성해주어 독립적임.
SQL mapper는 대표적으로 JDBC(Java Database Connectivity)가 존재하며 ORM은 JPA(Java Persistent API)가 존재한다. JDBC계층(Interface : Spring JDBC)는 Application 계층의 DAO와 Persistence계층의 DB사이를 매개하고, JPA는 외부 라이브러리로 JDBC를 사용하는 API로 JDBC계층과 Application계층 사이에 위치한다.
엄밀하게 말하면 JPA는 하나의 규약 및 표준이며 Hibernate는 JPA라는 규약을 따르는 프레임워크로써, JPA의 실질적 동작은 Hibernate에서 작동하고 있다.
Persistence Context과 Entity Manager
JPA가 생성하는 Layer는 persistence context라 하며, EntityManager에 의해 관리된다. Persistence context는 엔티티의 상태 변화를 추적하는 일종의 캐시 메모리로, 트랜잭션이 완료되기 전까지 데이터베이스에 직접 저장되지 않고 메모리에 저장된다. 트랜잭션이 완료되면, persistence context에 저장된 변경 사항이 데이터베이스에 flush되어 반영되며, 이를 통해 트랜잭션 중 빈번한 데이터베이스 작업으로 인한 부하를 줄인다.
이러한 지연된 flush 메커니즘 때문에 트랜잭션이 끝나기 전까지 변경 사항이 데이터베이스에 반영되지 않으며, 다른 트랜잭션이 동일한 데이터를 조회할 때 이러한 변경 사항을 볼 수 없습니다. 그러나 flush 후에 데이터베이스에 새로운 레코드가 추가되거나 기존 레코드가 삭제되면, 다른 트랜잭션이 동일한 쿼리를 실행할 때 새로운 데이터가 나타나거나 기존 데이터가 사라지는 phantom read 현상이 발생할 수 있습니다.
JDBC방식으로 데이터 저장하기
1. gradle에 spring-jdbc와 mysql 라이브러리 추가하기
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'mysql:mysql-connector-java'
2. application.properties 설정파일에 DB접속정보 입력하기
gradle을 통해서 dependency(jdbc와 mysql-java)를 설정해두었기 때문에 spring property 설정이 가능함.
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://local:3306/project?serverTimezone=UTC\
&characterEncoding=UTF-8
spring.datasource.username = root
spring.datasource.password =
JPA(ORM)방식으로 데이터 저장 설정하기
1. gradle에 spring-jdbc와 mysql 라이브러리 추가하기
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'mysql:mysql-connector-java:8.0.33' // 버전 명시
2.application.properties 설정파일에 DB접속정보 외 JPA설정 추가하기
- 자동생성 SQL쿼리문 보여주기
- 데이터베이스 mysql로 고지하기
spring.jpa.show-sql=true
spring.jpa.database=mysql
Entity 생성하기(Domain 생성하기, Table 생성하기)
Entity생성하기
자바클래스 중 DB Table과 연결할 클래스를 marking하기 위해서 @Entity을 사용한다. 또한, class명과 DB Table명이 다르다면 Class에 @Table(name="")을 통해서 어떤 테이블과 맵핑할 것인지 명시해줘야한다.
- @Entity(name = "tablename"(생략가능))
- @Table(name="")
TableColumn생성하기
그리고 Table column들의 속성을 셋팅해주는데, 어떤 필드를 PK로 지정하기 위해서 @Id를 쓰고, DB 내에서 autoincrement의 속성을 살리기위해서 @GeneratedValue(Strategy = GenerationType.IDENTITY)을 사용하여준다.
- @Id annotation : is used to specify the primary key of an entity.
- @GeneratedValue : 주로 JPA의 PK칼럼에 사용되며, 자동으로 값을 생성하는 방식을 설정한다.
- GenerationType.AUTO : JPA provider will choose an appropriate strategy for the particular database.
- DB에서 지원하는 값
- GenerationType.IDENTITY: DB에서 AUTO_INCREMENT가 적용되어 값을 생성해줄 때 해당 값을 수용한다는 의미
- GenerationType.SEQUENCE: The primary key is generated using a database sequence.
- GenerationType.TABLE: The primary key is generated using a table to ensure uniqueness.
- GenerationType.AUTO : JPA provider will choose an appropriate strategy for the particular database.
@Entity(name = "memo")
public class Memo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
private String text;
}- @Enumerated : to specify how a persistent enum type should be stored in the database when using JPA
- EnumType.ORDINAL : enum is stored in the database as an integer.
- EnumType.STRING : the enum is stored in the database as a string
- @Column
- (unique = true) : 유일값을 허락함
- (columnDefinition = "POINT") : to specify SQL-specific details about how a particular column in a table should be defined.
- (nullable = true) : null값을 허락함
- sql에서 해당 칼럼을 중복되지 않도록 unique, nullable keyword를 사용해서 셋팅해준다.
- @Table(uniqueConstraints ={@UniqueConstraint( columnNames = {})})
- 두개의 키의 조합이 유니크한 복합 유니크키를 설정해준다.
@Table(uniqueConstraints = {
@UniqueConstraint(
columnNames = {"companyId","date"})
})
public class DividendEntity {
- @ElementCollection
- 복수의 값을 담고 있는 List를 DB에 저장하기 위해서는 별도의 테이블을 만들어서 Join시키는 형태로 저장함.
@ElementCollection
private List<String> roles;
Entity생성시 고려사항
* Entity의 값을 변경하는 중요한 로직은 Entity class 외에서 실행하더라도, Entity내에서 메소드를 정의하고 이것을 호출하는 형식으로 진행할 필요가 있음. (Encapsulation, Static Factory)
* Entity의 자동생성ID외의 식별자는 일반적으로 UUID를 통한 유일한 생성자 생성에 많이 사용한다. ;
UUID.randomUUID().toString()
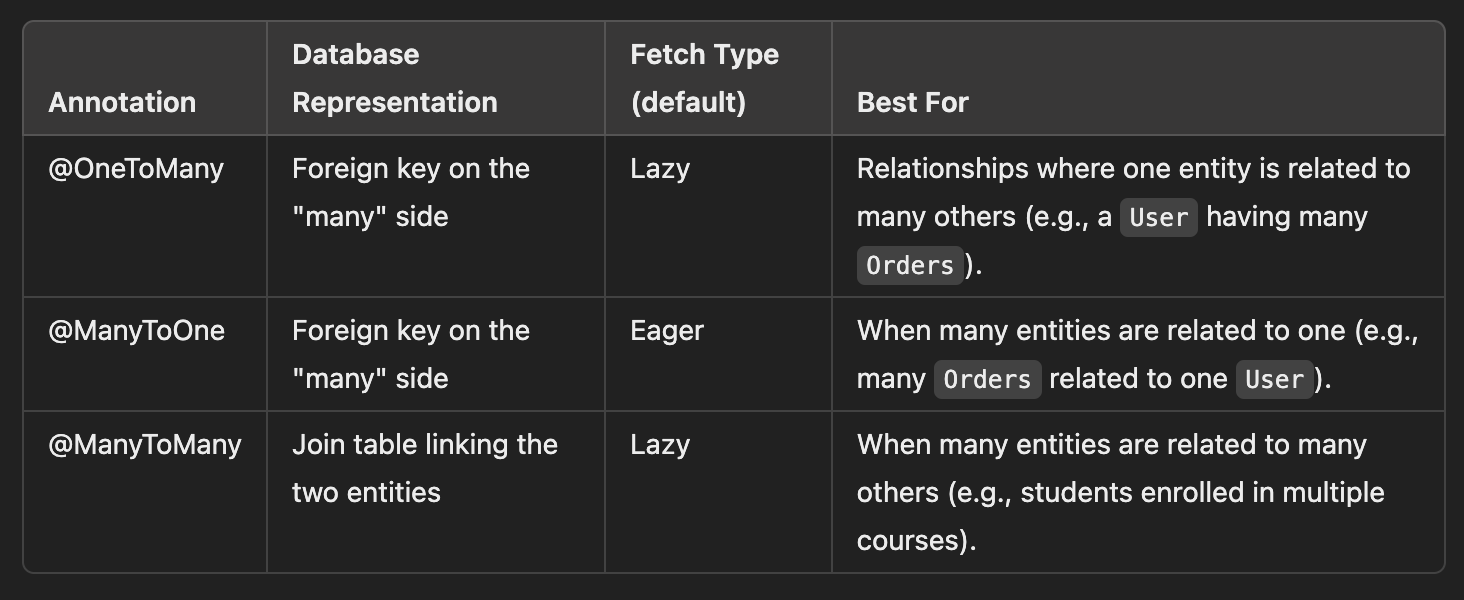
Entity Relation설정 - ManytoOne, ManytoMany
In a JPA-managed application, 다른 테이블과의 관계를 명시하기 위해서 (sql문의 foreign key처럼) 테이블의 일부 칼럼을 다른 Entity를 칼럼으로 사용한다. 그리고 @Manytoone과 같은 Annotation으로 테이블 간의 관계를 명시해준다. 이는 JPA의 내부 기능 및 코드 효율성 증진을 위한 것임.
- @ManytoOne
- 관계형테이블에서 흔하게 사용하는 설정으로 일대다 관계를 나타낸다. 실제 sql동작은 join문으로 연관테이블을 navigate한다. (OrderEntity가 UserEntity를 필드로 갖고 해당 Annotationi을 붙임)
- @JoinColumn : 두개의 Entity를 연결할때 FK를 명시적으로 설정하고 싶을때 사용한다. JPA는 manyToOne과 같은 관계 annotation이 붙으면 기본적으로 PK를 FK로 설정한다.
- @JoinColumn(name = "columnname", referencedColumnName = "columnname in other table", nullable = false) 해당 annotaion이 붙은 필드를 FK로 설정하며 columname을 칼럼명으로 한다.
- @JoinColumn : 두개의 Entity를 연결할때 FK를 명시적으로 설정하고 싶을때 사용한다. JPA는 manyToOne과 같은 관계 annotation이 붙으면 기본적으로 PK를 FK로 설정한다.
- @OnetoMany
- @ManyToOne 테이블에 종속적인 테이블로, (UserEntity 내에서 List<OrderEntity>를 필드로 갖고싶을때 해당 Annotation을 List에 붙인다,
- Unidirection을 Bidirection으로 만든다. 원래 UserEntity에서는 OrderEntity를 찾아갈 수 없는데, 찾아가는 경로를 만든셈과 같음. 실제로 SQL레벨에서는 OrderEntity 조회를 통해서 값을 return한다.
- 관계형테이블에서 흔하게 사용하는 설정으로 일대다 관계를 나타낸다. 실제 sql동작은 join문으로 연관테이블을 navigate한다. (OrderEntity가 UserEntity를 필드로 갖고 해당 Annotationi을 붙임)
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(mappedBy = "course")
private List<Student> students = new ArrayList<>(); // Course는 여러 Student를 참조함
}
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "course_id")
private Course course; // Student는 Course를 참조함
}
- @ManttoMany
- @ManyToMany 어노테이션은 다대다(Many-to-Many) 관계를 나타내며, 한 엔티티에서 여러 개의 다른 엔티티와 연결될 수 있는 경우에 사용됩니다. *학생(Student)**과 **수업(Course)**의 관계에서는 한 학생이 여러 수업에 참여할 수 있고, 한 수업에는 여러 학생이 참여할 수 있습니다. JPA에서는 mappedBy로 양방향성을 @JoinTable을 사용하여 조인테이블 세부설정을 관리합니다.
- @JoinTable : ManyToMany에서는 별도의 조인테이블이 생성되고 해당 테이블의 조회를 통해서 관계를 설정한다. 해당 annotation은 jointable을 정의하고, 해당 테이블을 커스터마이징할 수 있도록 해줍니다. 특별한 설정이없다면 JPA에서 자동적으로 설정하며 두 테이블의 PK를 FK로 설정하여 연결한다.
- name: 조인 테이블의 이름을 지정합니다.
- joinColumns: 주도권을 가진 엔티티의 외래 키를 설정합니다. 여기서는 student_id로 지정됩니다.
- inverseJoinColumns: 주도권을 갖지 않는 엔티티의 외래 키를 설정합니다. 여기서는 course_id로 지정됩니다.
- @JoinTable : ManyToMany에서는 별도의 조인테이블이 생성되고 해당 테이블의 조회를 통해서 관계를 설정한다. 해당 annotation은 jointable을 정의하고, 해당 테이블을 커스터마이징할 수 있도록 해줍니다. 특별한 설정이없다면 JPA에서 자동적으로 설정하며 두 테이블의 PK를 FK로 설정하여 연결한다.
- @ManyToMany 어노테이션은 다대다(Many-to-Many) 관계를 나타내며, 한 엔티티에서 여러 개의 다른 엔티티와 연결될 수 있는 경우에 사용됩니다. *학생(Student)**과 **수업(Course)**의 관계에서는 한 학생이 여러 수업에 참여할 수 있고, 한 수업에는 여러 학생이 참여할 수 있습니다. JPA에서는 mappedBy로 양방향성을 @JoinTable을 사용하여 조인테이블 세부설정을 관리합니다.
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id; // Primary Key of Student
private String name;
@ManyToMany
@JoinTable(
name = "student_course_mapping", // Custom join table name
joinColumns = @JoinColumn(name = "student_id"), // Custom foreign key column for Student
inverseJoinColumns = @JoinColumn(name = "course_id") // Custom foreign key column for Course
)
private List<Course> courses = new ArrayList<>();
}
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id; // Primary Key of Course
private String title;
@ManyToMany(mappedBy = "courses")
private List<Student> students = new ArrayList<>();
}
Entity Relation설정 - 양방향성 단방향성
양방향성과 단방향성
ORM에서는 테이블간의 관계를 설정할때 주도권이 있는 테이블과 주도권이 없는 종속적인 테이블을 나누어 구분하여 설정한다. 주도권을 갖은 테이블은 두 테이블의 연결에 대한 여러가지 설정을 할 수 있다. 그리고 거기에 더하여 테이블 간의 양방향성과 단방향성을 설정할 수 있다. 양방향성과 단방향성의 차이는, 단방향성에서는 주도권이 없는 엔티티를 조회할때, 관계되어있는 엔티티를 조회되지 않는데 양방향성에서는 조회가 된다는 것이다.
양방향성을 갖는 테이블의 조회는 한 record를 조회할때, 관계테이블의 다수의 record를 조회하게 될 수 도 있기때문에 성능상 설정의 고려를 잘해야한다. 양방성을 사용할때는 종속적인 테이블에서(예를들면 학생과 수업관계에서 수업) 연관된 주도적인 테이블의 record를 조회하고 싶을때 사용한다. 이때 eagerloading과 lazyloading을 적절하게 사용해야할 것
- 주도권을 가진 테이블: 관계의 주도권을 가진 테이블은 조인 테이블을 직접 관리하며, 데이터베이스에서 관계를 설정하거나 변경할 때 실질적인 제어를 합니다.
- 종속적 테이블: mappedBy 속성을 사용하여 다른 엔티티가 이 관계의 주도권을 가진다는 것을 명시합니다. 이는 주도권을 가진 쪽이 관계를 관리하며, 종속적 엔티티는 이를 단순히 참조하는 역할을 합니다.
- @ManyToMany(mappedBy = "courses") : 양방향(Bidirectional) 관계에서 사용됩니다. JPA에서는 양방향 관계를 설정할 때 한쪽이 관계의 **주도권(owner)**을 가지고, 다른 쪽은 주도권을 가지지 않는 종속적(non-owning) 관계로 설정됩니다.
단방향 관계(Unidirectional)
단방향 관계는 한쪽 엔티티에서만 다른 엔티티를 참조하는 관계입니다. 다른 엔티티는 이 관계를 인식하지 못하고, 일방적인 참조만 가능하게 됩니다.
OneToMany
Student와 Course가 있다고 가정했을 때, Student가 Course를 참조하지만 Course는 Student를 참조하지 않는 경우 단방향 관계입니다.
@Entity
public class Student {
@ManyToMany(fetch = FetchType.LAZY) // 지연 로딩
private List<Course> courses;
}
@Entity
public class Course {
@ManyToMany(mappedBy = "courses", fetch = FetchType.LAZY) // 지연 로딩
private List<Student> students;
}
Many-to-Many 단방향 관계
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses = new ArrayList<>();
}
양방향 관계(Bidirectional)
양방향 관계는 두 엔티티가 서로를 참조하는 관계입니다. 양방향 관계에서는 한쪽 엔티티가 다른 엔티티를 참조하고, 반대쪽에서도 다시 그 엔티티를 참조할 수 있습니다.
- 복잡한 비즈니스 로직 지원: 양쪽에서 데이터를 참조하고 수정해야 할 필요가 있을 때 사용됩니다.
- 성능에 주의 필요: 잘못된 로딩 방식(Eager Loading)을 사용할 경우, 순환 참조나 불필요한 데이터 로딩으로 인해 성능에 영향을 미칠 수 있습니다.
OnetoMany
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "course_id")
private Course course;
}
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(mappedBy = "course")
private List<Student> students = new ArrayList<>();
}
Fetching Strategy of Related Entity
Entity끼리 연결된 데이터를 입력할때, 혹은 데이터를 출력할때 저장/출력하려는 엔티티 뿐만아니라 연결된 엔티티까지 호출을 해야한다. 특히 연결된 엔티티가 collection 형태로 있으며 lazyloading으로 되어있어 collection이 loop될때마다 모든 entity마다 DB에서 fetch하는 경우 이를 N+1문제라고 하며, Entity로 테이블 간의 관계를 표현할때, ORM의 lazyloading이 기본값이므로 비효율성을 유발한다.
해당 비효율성을 감소시키기 위해서
A. LazyLoading/EagerLoading 전략을 설정할 수 있다. (Select문의 경우에는 .getUserEntity() 메소드가 실행되기 전에는 UserEntity를 조회하지 않도록 설정 한다)
B. JPQL로 select문을 사용하여 eagerloading 전용의 Method를 설정할 수 있다.
@Query("SELECT m FROM MemberEntity m JOIN FETCH m.visitedHeritages WHERE m.memberId = :memberId")
Optional<MemberEntity> findByMemberIdWithVisitedHeritages(@Param("memberId") String memberId);
C. Entity를 사용한 관계테이블 생성이아니라 별도의 관계형 Repository를 생성하여 해당 Repository로부터 직접 Fetch를 한다.
@Entity
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class VisitedHeritageEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String memberId;
@Column(nullable = false)
private String heritageId;
}
EAGER Fetching:
- When a relationship is marked as EAGER, JPA will automatically fetch the related entities when the parent entity is fetched. This means that when you select a record from a table, it will also fetch the related rows from the other table immediately.
LAZY Fetching:
- When a relationship is marked as LAZY, JPA will fetch the related entities on demand (i.e., when you explicitly access the relationship property). This is often the default fetching strategy in JPA.
두 엔티티가 밀접하여 연결되어 어차피 같이 Fetch해야한다면 EAGER Loading이 더 효율적일 수 있다.
Modifying Strategies of Related Entity
JPA에서 테이블 간의 관계가 있는 상황에서 관계를 변경하고자 하려면 관계로 표현되는 List와 Set을 전체 로딩해서 해당 Collection에서 변화를 만들어야한다. 이를 N+1 Select Problem or Over-fetching 이라고 한다.
Cascade Operation:
: 관계가 있는 두 테이블은 FK의 특성으로 인해서, 자식 테이블의 레코드가 모두 사라져야 부모테이블의 해당 레코드가 삭제될 수 있다. FK가 이를 강제한다. 마찬가지로 삽입도 부모 레코드에서 존재하는 데이터만 삽입가능하다. 하지만 이를 가능케하는게 Cascade Operation이다. 조심히 사용해야하는 편의기능이며 성능과는 무관하다. 나라면, 삭제할때 관련레코드는 순차적으로 직접삭제하도록 할것같다.
Repository 인터페이스 생성
JpaRepository를 상속하는 추상클래스를 만들고 이를 빈으로 등록하기 위해서 @Repository로 표기해줌. JpaRepository의 generics값은 <Repository의 Entity, PK타입>을 기입해주면 됨.
원리는 인터페이스가 생성되면 Spring Data JPA는 인터페이스로 호출된 method call을 dynamic proxy(런타임에 인터페이스를 구현한 클래스를 생성)를 통해서 repository의 method call을 인터셉트하여, 클래스에서 method call을 하이버네이트에 의뢰하여 SQL쿼리를 생성해주는 방식임.
해당 인터페이스에서 메소드를 정의하면 Repository extention에 의해서 메소드 이름에 걸맞도록 sql문이 생성된다. 그외에도 @Query("sql쿼리문")과 같이 sql쿼리를 직접 커스터마이징한 메소드를 생성할 수 있다.
@Repository
public interface JpaMemoryRepository extends JpaRepository<Memo,Integer> {
}@Query("SELECT u FROM User u WHERE u.email = ?1")
User findByEmail(String email);
repository static method
- findbyId : Id를 기준으로 해당하는 엔티티를 반환
- save() : PK에 해당하는 엔티티가 존재하지 않으면 create, 존해자면 update 함.
- saveAll() : Entity가 List형태로 보관되어 있을 때 전부 저장한다.
- existById() : Id로 해당 record가 존재하는지 검색하여 boolean값을 반환한다. Custom property를 사용하여 구현도가능
- findAllByIdStartingWithIgnoreCase : SQL문으로 WHERE UPPER(Id) LIKE UPPER('sam%')로 대소문자 구분없이 특정 키워드로 시작하는 ID값을 전체 조회하여 List 형태로 받는다.
메소드 이름을 설정할때 아래와 같은 규칙을 따라서 생성해야 정확한 sql문 생성하는 메소드를 정의할 수있다.
커스텀 method 생성시 Method Naming 룰 in Spring Data JPA
- Start with a Prefix: such as (find...By = read...By =query...By= get...By), count...By, and. findfirstb
- Specify the Criteria: After the prefix, continue with a property name of the entity you are querying.
- Conditions and Keywords: . Some common keywords include Containing, Between, LessThan, GreaterThan, Like, In, StartsWith, EndsWith, and more.
- Connecting Keywords: For methods that involve multiple properties, you can use connecting keywords like And and Or to combine conditions.
- Handling Collections: If you are dealing with collections, you can use expressions like IsEmpty, IsNotEmpty, In, etc., to express conditions on the collections.
- Ordering Results: You can specify the order of the results by appending OrderBy followed by the property name and direction (Asc or Desc) at the end of the method name.
쿼리시에 값이 존재하지 않아서 DB에서 아무 응답도 없는 경우도 있기 때문에 이 예외처리를 위해서 Optional<Domain>으로 값을 받아주고 optional.else로 예외처리를 해준다.
Optional<User> findByEmailAddressAndLastName(String email, String lastName);
Optional<User> findByAgeGreaterThanEqual(int age);
Optional<User> findByLastNameIgnoreCase(String lastName);
Optional<User> findByStartDateBetween(Date start, Date end);
Optional<User> findByActiveTrue();
Optional<User> findByAgeIn(Collection<Integer> ages);
Optional<User> findByLastNameOrderByFirstNameAsc(String lastName);
6. 기타
1. Auditing functionality : Persistency Layer에서 특정 이벤트 발생시에 자동적으로 데이터값을 생성해주는 기능을 말한다. 레코드 생성자, 생성일 등 데이터의 히스토리를 추적하는데 사용된다. 적용할 Entity에 아래의 EntityListeners를 생성하고 @CreatedDate
@LastModifiedDate와 같이 entitylistner을 심어둔다. 이 entitylistener들은 entity의 lifecycle을 파악하고 lifecycle의 특정부분에 지정된 코드를 실행하도록 한다.
@EntityListeners(AuditingEntityListener.class)@Configuration
@EnableJpaAuditing
public class JpaAuditingConfiguration {
}
2. 데이터 직접입력하기 :
(1) Spring directory - resource - 아래에 data.sql이라는 문서를 만들고 이곳에서 Insert query를 작성. 반드시 'data.sql이어야만 인식을 함.
(2) spring property 설정에 defer datasource initialization이라는 값을 설정하여, hibernate의 ddl-auto가 table을 생성을 완료한후에야 Insert문을 실행하도록 설정한다.
jpa:
defer-datasource-initialization: true
Page & Pagable
Page : a Spring Data interface that represents a subset of data— a slice of the database that contains information about the total number of elements, total pages, the current page content, and navigation links (next, previous). 해당 페이지에 대한 메타데이터는 Pageable형식으로 포함된다.
Pageable : Pageable is an interface provided by Spring Data that encapsulates pagination information, including which page to retrieve, how many items each page should contain, and the sorting criteria for the items.
Controller Layer:
- Role: Receives pagination parameters (like page number, page size, sort order) directly from API requests.
- Example: API endpoints에서 parameter을 pageable로 설정하면, pageable내 fieield값으로 여러가지 값을 갖고 이를 parameter로 "?page=2&size=10&sort=name,asc" 전달해서 원하는 page를 return 받을 수 있다.
@GetMapping
public ResponseEntity<?> searchCompany(final Pageable pageable) {
Page<CompanyEntity> companies = companyService.getAllCompany(pageable);
return ResponseEntity.ok(companies);
}
Service Layer:
- Role: 서비스 계층에서 repository를 호출하여 pageable을 Input하면 Page를 반환한다. Sometimes it might transform entities within the Page to DTOs to send to the controller.
- Example: Conversion from Page<Entity> to Page<DTO> if necessary, applying any additional business logic.
Repository Layer:
- Role: Utilizes Pageable directly in repository methods to fetch data from the database.
쿼리문을 통한 Repository method 정의
- @Query allows you to define custom SQL queries. If you need to write native SQL (SQL specific to the database you're using, such as MySQL, PostgreSQL, etc.), you can specify nativeQuery = true.
- @Modifying : is required for INSERT, UPDATE, and DELETE queries. 그렇지않으면 select문으로 인식하고 처리함.
- modifying은 해당 sql문이 데이터베이스의 변화를 주는지 표시하는 것이며 결과값으로 변화가 생긴 row의 개수를 반환한다.
- :paramName : You can use named parameters (like :paramName) or positional parameters (?1, ?2, etc.) in native queries.
- @Transactional : If you're performing bulk updates or deletes, ensure that the method is annotated with @Transactional, especially for data modification queries.
필요성
JPA의 method를 통해서 많은 부분들이 추상화되었지만 여전히 SQL작성은 필요함. 아래와 같은 케이스가 그 케이스임.
1. 전송되는 데이터 볼륨을 줄이기 위해서는 데이터베이스에서 전처리를 한 후 필요한 데이터만 송출되어야하기 때문이다.
2. JPA에서 제공하는 메소드만으로는 구현하기 어려운 디테일한 작업의 경우에는 JPQL을 사용한다.
이럴때 @Query annotation을 사용해서 Native SQL이나 JPQL을 사용할 수 있다. 일반적으로 아래와 같은 장점으로 JPQL을 더 많이 사용된다.
1. Database와 무관하여 추상화되어있기때문에 DB가 바뀌어도 JPQL을 바꿀필요가 없어서 유지보수성이 좋다
2. DB가 대상이 아니라 Entity를 대상으로 사용하기때문에 MantToMany에 Table을 생성할 필요가 없다던지 ORM에 최적화되어있음
// Custom query to calculate the average rating for a specific store
@Query("SELECT AVG(r.rating) FROM ReviewEntity r WHERE r.storeEntity = :storeEntity")
Double findAverageRatingByStore(@Param("storeEntity") StoreEntity storeEntity);
}
JPQL(Java Persistence Query Language) specific
- select entity(or alias) : use 'select entity' instead of 'select *'
- namedParameter : ':parameterName'는 :로 표기함으로써 특정 변수를 나타냄
- @Param: query문 내에서 placeholder의 이름을 정할 수 있다. 위의 쿼리문에서 :storeEntity는 placeholder역할을 할뿐이고 @param로 표기된 인수를 을 해당 쿼리문에 넣는다는 의미.
- JOIN FETCH : 테이블을 Join 시키면서 Join하는 테이블을 eager fetch하도록 한다.
@Query("select v.heritageEntity from VisitedHeritageEntity v join fetch v.heritageEntity where v.memberEntity.memberId = :memberId")
List<HeritageEntity> findAllVisitedHeritageByMemberId(String memberId);
SQL과 JPQL 비교
ManyToMany 관계일때, Entity는 이미 annotation을 통해서 Join 관계가 형성되어 있어 이를 이용하여 간단한 JPQL이 가능하지만
SQL은 query마다 table join을 메뉴얼로 하여야하기때문에 문장이 훨씬 길다.
@Query("SELECT v FROM Visitor v JOIN v.visitedSites s WHERE s.name = :siteName")
List<Visitor> findVisitorsByHeritageSiteName(@Param("siteName") String siteName);
@Query(value = "SELECT v.* FROM visitor v " +
"JOIN visitor_heritage vh ON v.id = vh.visitor_id " +
"JOIN heritage_site hs ON hs.id = vh.heritage_site_id " +
"WHERE hs.name = :siteName", nativeQuery = true)
List<Visitor> findVisitorsByHeritageSiteNameNative(@Param("siteName") String siteName);
Field Names Convention
- 엔티티 필드 이름은 카멜 케이스로 작성하지만, 데이터베이스의 컬럼명은 보통 **스네이크 케이스(snake_case)**로 작성됩니다.
boolean existsByMemberEntity_MemberIdAndHeritageEntity_HeritageId(String memberId, String heritageId);
- 엔티티 필드가 단순한 원시 타입(예: String, int)이 아닌, 다른 엔티티와의 관계를 나타낼 때가 많습니다. 이 경우, VisitedHeritageEntity는 다른 엔티티와 다대일(@ManyToOne) 관계를 통해 연결되어 있기 때문에, Spring Data JPA가 쿼리를 생성할 때는 이 엔티티와 연결된 필드(FK)까지 정확히 명시해주어야 합니다.
'개발기술 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 기술개념 - [북스터디] 데이터 베이스를 지탱하는 기술 (0) | 2024.08.05 |
|---|---|
| DB 트랜잭션 (0) | 2024.07.25 |
| 데이터 관계와 모델링, ERD작성 (0) | 2024.07.13 |
| SQL문 정리 (0) | 2024.07.09 |
| 데이터베이스 환경구축 (Maria DB 초기설정, JDBC사용,JPA설정) (0) | 2024.05.02 |
