그래프이론 알고리즘/자료구조
그래프 이론의 필요성
높은 수준의 프로그래밍을 하기 위해서는 그래프이론에 대한 탄탄한 이해가 필수적이다. 프로그래밍의 발전은 결국 정보의 연결성의 증대에 의한, 연결성 증대를 위한 방향으로 발전하고 있기 때문이다. 예를 들어, FaceBook과 같은 연결형 SNS, Google과 같은 검색엔진, Netflix와 같은 추천서비스, Amazon과 같은 동선최적화, OpenAI와 같은 자연어처리 등 모두 내가 선택한 Node로부터 주변 Node를 탐색하는 문제이기때문이다.
고등수학에서 잘 다루지 않아서 익숙하지 않은 것이지 어려운 것은 아니라고 생각한다. 높은 수준의 프로그래머가 되기 위해서는 결국엔 선형대수학을 어느정도는 이해해야 할 것이고 그것의 근본이 그래프 이론이니 지금부터 피할 수 없는 기초를 쌓아나간다고 생각하고 조금씩 정진해 나가자. 오히려 기회다.
그래프 이론 (Edge and Vertex)
그래프 자료구조
- 연결되어 있는 원소들간의 관계를 표현하는 자료구조이다. 그래프는 G(V, E)로 정의하고, V(Vertext : 정점)과 E(Edge : 간선) 의 집합을 의미한다.
- 보통 시작하는 Vertex로부터 이웃한 Vertex를 표현하는 Adjacency(인접)이라는 개념으로 표현한다.
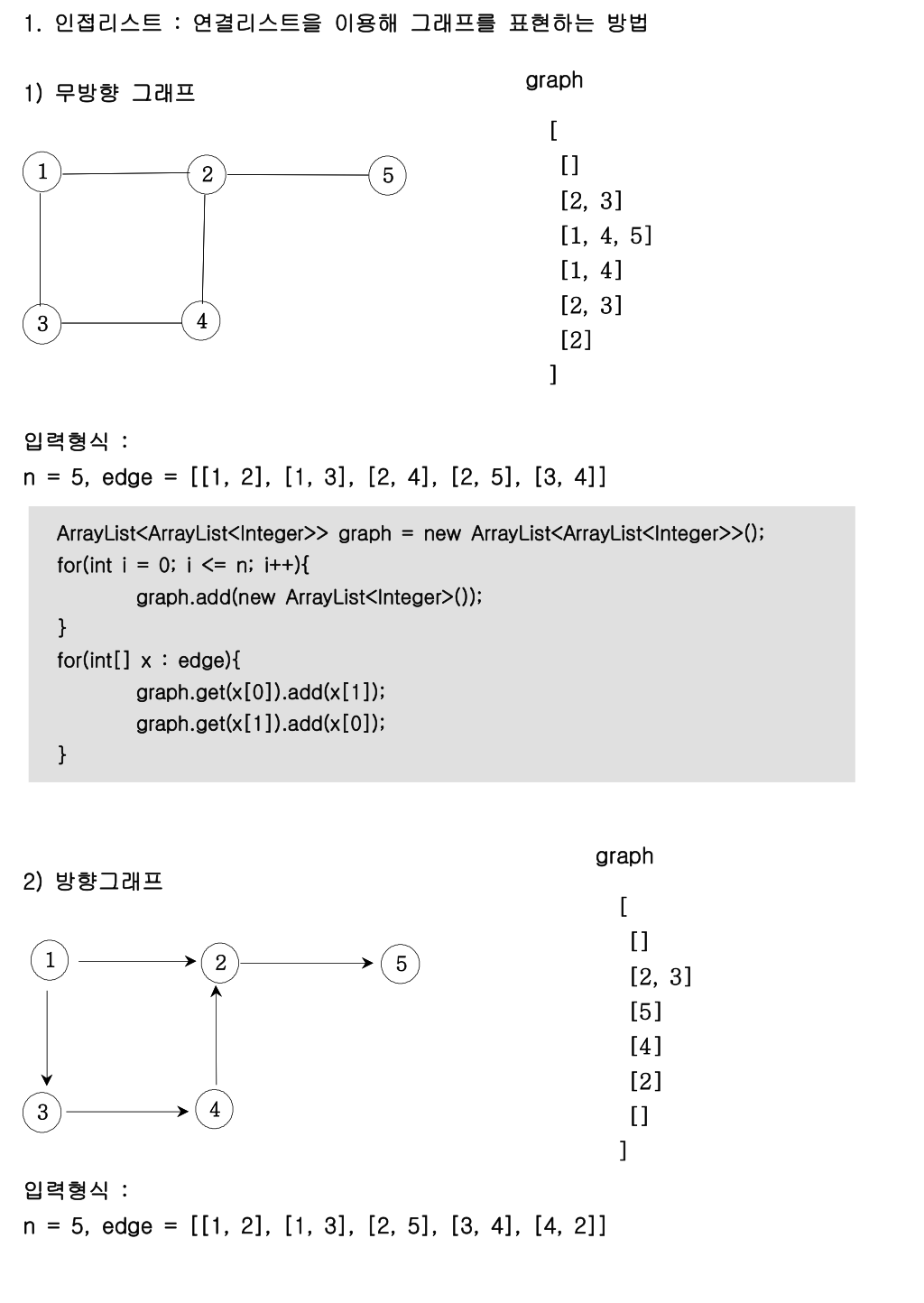
- *인접리스트 : 각 리스트의 index가 탐색을 시작하는 Vertex를 의미하는 리스트이며 각 index의 데이터는 이웃하는 Vertext를 의미 for each vertex u ∈V, Adj[u] stores u’s neighbors, i.e., {v ∈V |(u, v) ∈E}.
- 인접행렬 : 인접리스트를 2차원 배열을 이용해 표현하는 방법.
- 인접함수 :Adj(u) is a function — compute local structure on the fly
- Object-oriented 인접함수 : object for each vertex u, u.neighbors = list of neighbors i.e. Adj[u]
인접리스트 표현법
edge들을 탐색해서 시작 Vertex를 index에 위치한 List에 갈수 있는 Neighbor 객체를 추가하는방식. 코테에서 인접리스트 사용이 선호된다.
그래프이론으로 정의되는 문제
- 그래프 탐색문제 : 그래프를 노드별 관계(함수 혹은 adj list 등)를 활용하여 노드별로 탐색한 후 특정한 동작(함수)를 실행함.
- 노드를 개체의 특정한 상태(state)로 바라볼 수 있으며, 각 노드는 개체의 attribute 값이 다른 상태로 생각할 수 있음. 그래프 문제는 이 노드에 해당하는 개체와 개체의 attribute, attribute를 바꾸는 method 관계인 엣지를 어떻게 구현하느냐이다. 나아가 시간복잡도 최적화를 위해서 엣지 커트를 어떻게 구현할 것인지에 대한 문제이다.
Comparision Model and Decision Tree
- In this model, comparable objects can be thought of as black boxes, supporting only a set of binary boolean operations called comparisons (namely <, ≤, >, ≥, =, and !=).Each operation takes as input two objects and outputs a Boolean value, either True or False, depending on the relative ordering of the elements.
- Binary Search
- There must be a leaf for each possible output to the algorithm. the worst-case number of comparisons that must be made by any comparison search algorithm will be the height of the algorithm’s decision tree which is Log n
DFS와 For/if문 차이
- 경우의 수 관점에서는 컴퓨터의 모든 동작은 tree로 나타낼 수 있다. 분기를 활용하는 if/for문 그리고 재귀함수(DFS,BFS)는 결국 동일하게 tree와 같이 분기를 형성한다. for문/if문과 재귀함수의 차이는, for/if문은 분기의 중첩개수가 for/if구문의 개수에 따라 유한하지만 DFS의 경우 parameter를 통해서 개수를 설정할 수 있다는 것이다.
- 주로, 구조는 DFS 함수 내에서 for문이 존재하고 for문의 중첩개수 혹은 중첩구조를 DFS 함수 parameter로 custom함.
DFS와 BFS 설계고려요소
- 1. main logic : node에 도달하엿을때 어떤 기능을 실행할 것인가 (for문, stack의 push pop, chk의 =1,0)
- 2. parameter : 어떤 parameter을 갖고서 노드 간의 관계 (edge)는 어떻게 정의할 것인지?
- 3. edge cut : 언제까지 재귀함수를 실행시킬 것이며 edge cut가 필요하다면 어떻게 구현할 것인지?
- DFS와 BFS 모두 경로탐색을 목적으로하지만 DFS은 depth를 우선으로 탐색하기 때문에, depth가 너무 깊은 경로의 경우 수행시간이 무한정 오래 걸릴 수 있다. 반면 BFS는 level별 탐색이기때문에 최단경로 탐색에 적합하다.
DFS (Depth First Search)
- recursively explore and backtrack along breadcrumbs until reach unexplored neighbor. careful not to repeat a vertex. 탐색가능한 경로 중 더이상 탐색이 불가할 때까지 순차적으로 탐색하는 방법.
Adjacency list로 정의된 DFS
시작점을 Index로 하여 adj list를 조회를 통해 neighbor을 확인하고 s를 neighbor의 parents로 저장함. neighbor의 Parent가 등록여부를 확인하여 Visited Vertex인지 확인하는 구조. BFS와는 달리, adj를 조회하는 시점에서 재귀함수를 호출하여 stack구조로 조회를 확장시켜나감
def dfs(Adj, s, parent = None, order = None): # Adj: adjacency list, s: start
2 if parent is None: # O(1) initialize parent list
3 parent = [None for v in Adj] # O(V) (use hash if unlabeled)
4 parent[s] = s # O(1) root
5 order = [] # O(1) initialize order array
6 for v in Adj[s]: # O(Adj[s]) loop over neighbors
7 if parent[v] is None: # O(1) parent not yet assigned
8 parent[v] = s # O(1) assign parent
9 dfs(Adj, v, parent, order) # Recursive call
10 order.append(s) # O(1) amortized
11 return parent, order
CutEdge로 중첩횟수를 제한한 DFS
(+본 logic에 DFS 두번넣어 edge간 관계표현)
// n ... 5, 4, 3, 2, 1
public void Dfs1(int n){
if(n == 0) // cutedge
return;
else{
System.out.print(n + " "); // main logic
Dfs1(n-1); // exploring
}
}
// 1, 2, 3, 4, 5...
public void Dfs2(int n){
if(n == 0) // cutedge
return;
else{
Dfs2(n-1); // exploring
System.out.print(n + " "); // main logic
}
}
// 1, 2, 4, 5, 3, 6 ,7 전위순회 tree exploration, 중위 및 후위는 순서만 바꾸면됨
public void Dfs3(int v){
if(v > 7) // cutedge
return;
else{
System.out.print(v + " "); // main logic
Dfs3(v*2); // exploring
Dfs3(v*2+1); // exploring
}
}
Parameter로 중첩 횟수를 정의한 DFS
- parameter들은 변형을 시키고 난 후 다음 node로 넘겨줘서는 안되고, parameter가 변경되는 식 자체를 다음 node로 넘겨주어야함.
- stk을 통해서 depth에 따른 결과물들을 저장하는 dfs
// 중복순열- 서로 다른 n개의 원소를 가지는 어떤 집합에서 중복과 상관없이 순서에 상관있게 r개의 원소를 선택하거나 혹은 나열하는것
Stack<Integer> pm = new Stack<>();
public void Dfs1(int Level, int n, int r) {
if (Level == r) { // cut edge
for (int x : pm) {
System.out.print(x + " ");
}
System.out.println();
} else { // main logic
for (int i = 1; i <= n; i++) {
pm.push(i);
Dfs(Level + 1, n, r); // exploration
pm.pop();
}
}
}
CHK로 중복을 제거하는 DFS
- stk는 static으로 보관하는 반면, chk는 static으로 생성하지 않고
// 순열 : 서로 다른 n개의 원소를 가지는 어떤 집합에서 '중복 없이' '순서에 상관있게' r개의 원소를 선택하거나 혹은 나열하는 것
Stack<Integer> stack = new Stack<>();
public void Dfs2(int L, int n, int r, int[] ch) {
if (L == r) {
for (int x : pm) {
System.out.print(x + " ");
}
System.out.println();
} else {
for (int i = 1; i <= n; i++) {
if (ch[i] == 0) {
ch[i] = 1;
pm.push(i);
Dfs2(L + 1, n, r, ch);
ch[i] = 0;
pm.pop();
}
}
}
}
Str과 End을 조정해서 분기를 만드는 DFS
Stack<Integer> combi = new Stack<>();
public void DFS(int L, int s, int n, int r) {
if (L == r) {
for (int x : combi) System.out.print(x + " ");
System.out.println();
} else {
for (int i = s; i <= n; i++) {
combi.push(i);
DFS(L + 1, i + 1, n, r);
combi.pop();
}
}
}BFS Breadth First Search
- Explore graph level by level from s
- build level i > 0 from level i−1 by trying all outgoing edges, but ignoring vertices from previous levels.
- BFS는 최단거리를 손쉽게 찾아낼 수 있다. 반면 DFS는 전수 탐색을 마쳐야만 최단거리를 비교를 통해서 찾아낼 수 있음.
- BFS 문제풀이 특징
- 횟수라는 단어가 들어간다면 BFS탐색 문제이다
- 갔던 경로는 다시 방문하지 않도록 int[] chk를 활용해서
Adjacency list로 정의된 BFS
- 시작점을 level 0으로 저장함. 그 후 시작점을 Index로 하여 adj list를 조회를 통해 neighbor을 확인하고 이를 next level로 저장함. edge in level을 통해서 visited vertex인지 확인하는 구조. DFS와는 달리 level을 모두 조회 후 level = next level로 assignment 하는 반복 구조로 조회를 확장함.
1 def bfs(Adj, s): # Adj: adjacency list, s: starting vertex
2 parent = [None for v in Adj] # O(V) (use hash if unlabeled)
3 parent[s] = s # O(1) root
4 level = [[s]] # O(1) initialize levels
5 while 0 < len(level[-1]): # O(?) last level contains vertices
6 level.append([]) # O(1) amortized, make new level
7 for u in level[-2]: # O(?) loop over last full level
8 for v in Adj[u]: # O(Adj[u]) loop over neighbors
9 if parent[v] is None: # O(1) parent not yet assigned
10 parent[v] = u # O(1) assign parent from level[-2]
11 level[-1].append(v) # O(1) amortized, add to border
12 return parent
How fast is breadth-first s
Que로 정의된 BFS
DFS가 Stack을 활용하여 LIFO순서로 전개해 나간다면, BFS는 que를 활용하여 FIFO순서로 전개해 나간다.
1. CutEdge는 nextnode가 queue에 들어가기 전에 cut
- 중복 check list는 nextnode가 queue에 들어가는 순간 1로 표기
2. 현재 node poll 후 순회로직에 따라서 nextnode 생성하여 queue에 삽입
int BFS(int root, int target) {
Queue<Integer> queue = new LinkedList<>();
// que 생성하여 root 삽입 + 방문한 노드는 chklist에 chk
int[] chk = new int[10000 + 1];
int level = 0;
queue.add(root);
chk[root] = 1;
while (!queue.isEmpty()) {
//레벨 증가후,queue 안의 node 개수만큼 poll할 횟수 결정
int loopNumber = queue.size();
for (int i = 0; i < loopNumber; i++) {
int node = queue.poll();
// 노드에 도착한 후의 로직실행
System.out.println(node);
if (node == target) {
//값 배치후 loop에서 탈출
return result;
}
// 다음 노드를 전개하여 큐에 저장
for (int nextnode :
new int[]{node + 1, node - 1, node + 5}) {
//큐에 들어가기 전 cutedge실행
if (nextnode > 0 && chk[nextnode] == 0) {
queue.add(nextnode);
//중복제외
chk[nextnode] = 1;
}
}
}
level++;
}
return -1;
}
BloodFill
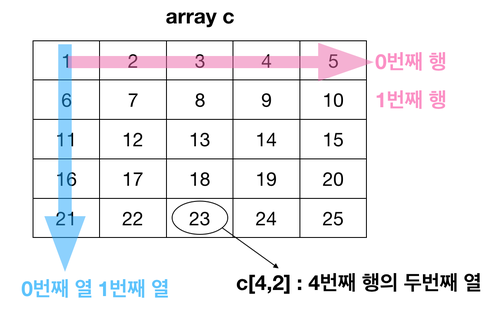
2차원배열 : int[row][column]
{
{array1 .............}, row0
{array2 .............}, row1
{array3 .............}, row2
{array4 .............}, row3
{array5.............}, row4
{array6.............}, row5
{array7.............}, row6
}
DFS와 BloodFill
BFS와 BloodFill
Divide&Conquer와 BloodFill